

With recent advances in machine learning, we could be entering a period of technological progression more impactful than the Scientific Revolution and the Industrial Revolution combined. The development of transformer architectures and massive deep learning models trained on thousands of GPUs has led to the emergence of smart, complex programs capable of understanding and producing language in a manner indistinguishable from humans.
The notion that text is a universal interface that can encode all human knowledge and be manipulated by machines has captivated mathematicians and computer scientists for decades. The massive language models that have emerged in the previous handful of years alone are now proof that these thinkers were onto something deep. Models like GPT-4 are already capable of not only writing creatively, but coding, playing chess, and answering complex queries.
The success of these models and their rapid improvement through incremental scaling and training suggests that the learning architectures available today may soon be sufficient to bring about a general artificial intelligence. It could be that new models will be required to produce AGI, but if existing models are on the right track, the path to artificial general intelligence could instead amount to an economics problem — what does it take to get the money and energy necessary to train a sufficiently large model?
At a time of such mind-blowing advancement, it’s important to scrutinize the foundations underpinning technologies that are sure to change the world as we know it.
The Powers of LLMs
Large language models like GPT-4 or GPT-3 are the most powerful and complex computational systems ever built. Though very little is known about the size of OpenAI’s GPT-4 model, we do know that GPT-3 is structured as a deep neural network composed of 96 layers and over 175 billion parameters. This means that just running this model to answer an innocent query via ChatGPT requires trillions of individual computer operations.
After it was released in June 2020, GPT-3 quickly demonstrated it was formidable. It proved sophisticated enough to write bills, pass an MBA exam at Wharton, and be hired as a top software engineer at Google (eligible to earn a salary of $185,000). Also, it could score a 147 on a verbal IQ test, putting it in the 99th percentile of human intelligence.
However, those accomplishments pale in comparison to what GPT-4 can do. Though OpenAI remained particularly tight-lipped about the size and structure of the model, apart from saying that “over the past two years, we rebuilt our entire deep learning stack and, together with Azure, co-designed a supercomputer from the ground up for our workload,” it shocked the world when it revealed just what this entirely redesigned model could do.
At one point, the commonly accepted way of detecting human-level computer intelligence was the Turing test. If a person could not distinguish whether they were conversing with a human or a computer via speech alone, then it could be concluded the computer was intelligent. It’s now clear that this benchmark has outlived its relevance. Another test is needed to pinpoint just how intelligent GPT-4 is.
As rated by a variety of professional and academic benchmarks, GPT-4 is essentially in the top 90th percentile of human intelligence. It scored above 700s in SAT Reading & Writing and SAT Math, which is sufficient for admission to many Ivy League universities. It also scored 5s (the top score possible on a scale of 1 to 5) in AP subjects ranging from Art History, Biology, Statistics, Macroeconomics, Psychology and others. Remarkably, it can also remember and refer to information sourced from up to 25,000 words, meaning that it can respond to a prompt spanning up to 25,000 words.
In fact, calling GPT-4 a language model isn’t quite right. Text isn’t all that it can do. GPT-4 is the first multimodal model ever produced, meaning it can decipher both text and images. This means that it can understand and summarize the context of a physics paper just as easily as it can understand and summarize the context of a screenshot of a physics paper. Outside of that, it can also code, school you in the Socratic method, and compose anything from screenplays to songs.
The Magic of the Transformer Model
The secret to the success of large language models is their unique architecture. This architecture emerged just six years ago and has since gone on to rule the world of artificial intelligence.
When the field first emerged, the operating logic was that every neural network should have a unique architecture geared toward the particular task it needed to achieve. Creating a neural network that could decipher images required one structure, while creating a neural network that could read would need another. However, there remained those who believed that in the same way a chip architecture can be generalized to execute any program, there might exist a neural network structure that could be capable of performing any task you asked of it. For example, Open AI CEO Sam Altman wrote in 2014, that
"Andrew Ng, who ... works on Google’s AI, has said that he believes learning comes from a single algorithm — the part of your brain that processes input from your ears is also capable of learning to process input from your eyes. If we can just figure out this one general-purpose algorithm, programs may be able to learn general-purpose things."
Between 1970 and 2010, the only real success that the field of artificial intelligence saw was in computer vision. Creating neural networks that could break a pixelated image into elements like corners, rounded edges, and so on eventually made it possible for AI programs to recognize objects. However, these same models didn't work as well when given the task of parsing the nuance and complexities of language. Early natural language processing systems kept messing up the order of words, suggesting that these systems were unable to correctly parse syntax and understand context.
It was not until a group of Google researchers in 2017 introduced a new neural network architecture specifically catering to language and translation that all this changed. The researchers wanted to solve the problem of translating text, a process that required decoding meaning from a certain grammar and vocabulary and mapping this meaning onto an entirely separate grammar and vocabulary. This system would need to be incredibly sensitive to word order and nuance, all while being cognizant of computational efficiency. The solution to this problem was the transformer model, which was described in detail in a paper called "Attention Is All You Need".
Rather than parsing information one bit after the other like previous models, the transformer model allowed a network to retain a holistic perspective of a document. This let it make decisions about relevance, retain flexibility with things like word order, and more importantly understand the entire context of a document at all times.
A neural network that could develop a sense of a total document's context was an important breakthrough. In addition, transformer models were faster and more flexible than any prior models. Their ability to cleverly translate from one format to another also suggested that they would be able to reason about a number of different types of tasks.
Today, it's clear that this was indeed the case. With a few tweaks, this same model could be trained to translate text into images as easily as it could translate English into French. Researchers from every AI subdomain were galvanized by this model, and quickly replaced whatever they were using before with transformers. This model's uncanny ability to understand any text in any context essentially meant that any knowledge that could be encoded into text could be understood by the transformer model. As a result, large language models like GPT-3 and GPT-4 can write as easily as they can code or play chess — because the logic of those activities can be encoded into text.
The past few years have been a series of tests on the limits of transformer models, and so far none has been established. Transformer models are already being trained to understand protein structure, design artificial enzymes that work just as well as natural enzymes, and much more. It's looking increasingly like the transformer model might be the much sought-after generalizable model. To drive the point home, Andrej Karpathy, a deep learning pioneer who contributed massively to the AI programs OpenAI and Tesla, recently described the transformer architecture as "a general purpose computer that is trainable and also very efficient to run on hardware.”
The Neural Network
The inspiration behind the design of neural networks lies in biology. Building a computer structured like a human brain was an idea that Alan Turing had already come up with in the 1930s, but it would take another couple of decades for humans to learn about brain structure in greater detail. It was known that brains were made of cells called neurons, connected together by channels called axons.
It was further estimated that there were billions of neurons and trillions of axons inside a single human brain, but it was not until 1949 that Donald Hebb proposed how all these neurons were wired up to produce intelligent behavior. His theory, called cell assembly, stated that “assemblies of neurons could learn and adapt by adjusting the strength of their interconnections.” The potential of this concept seriously inspired leading computer scientists of the time, particularly the young duo of Wesley Clark and Belmont Farley, two researchers at MIT. They figured that if they built a similar structure of neural units using computers, something interesting might come out of it. They called their structure a ‘neural network’ and published the results of their work in a 1954 paper called “Generalization of Pattern Recognition in a Self-Organizing System.”
The intuition for why a network organized like a neural network would be so effective at processing information, however, is illustrated in another paper from 1959 called “Pandemonium: A Paradigm for Learning.” Pandemonium means den of demons. This was the name for the capital of hell in John Milton’s Paradise Lost, and this paper may or may not be the reason that Elon Musk refers to developing AI as “summoning the demon.”
In this context, however, Pandemonium is a hierarchical organization of demons. At the bottom of the pyramid are what the paper’s author Oliver Selfridge calls “data demons.” Each data demon is responsible for looking at some portion of input data, whether that input data be an image of a letter or a number, or something else entirely. Each demon looks for something specific and “shouts” to a higher class of demon if it finds what it’s looking for. The volume of their screams determines the certainty with which they’ve observed what they’re looking for. Above the data demons are a layer of manager demons, trained to listen to particular sets of data demons. If they hear from all their underlings, they too will shout up to their managers, until finally the message is carried up to the top “decision demon,” who can make a final decision about what image Pandemonium is looking at.
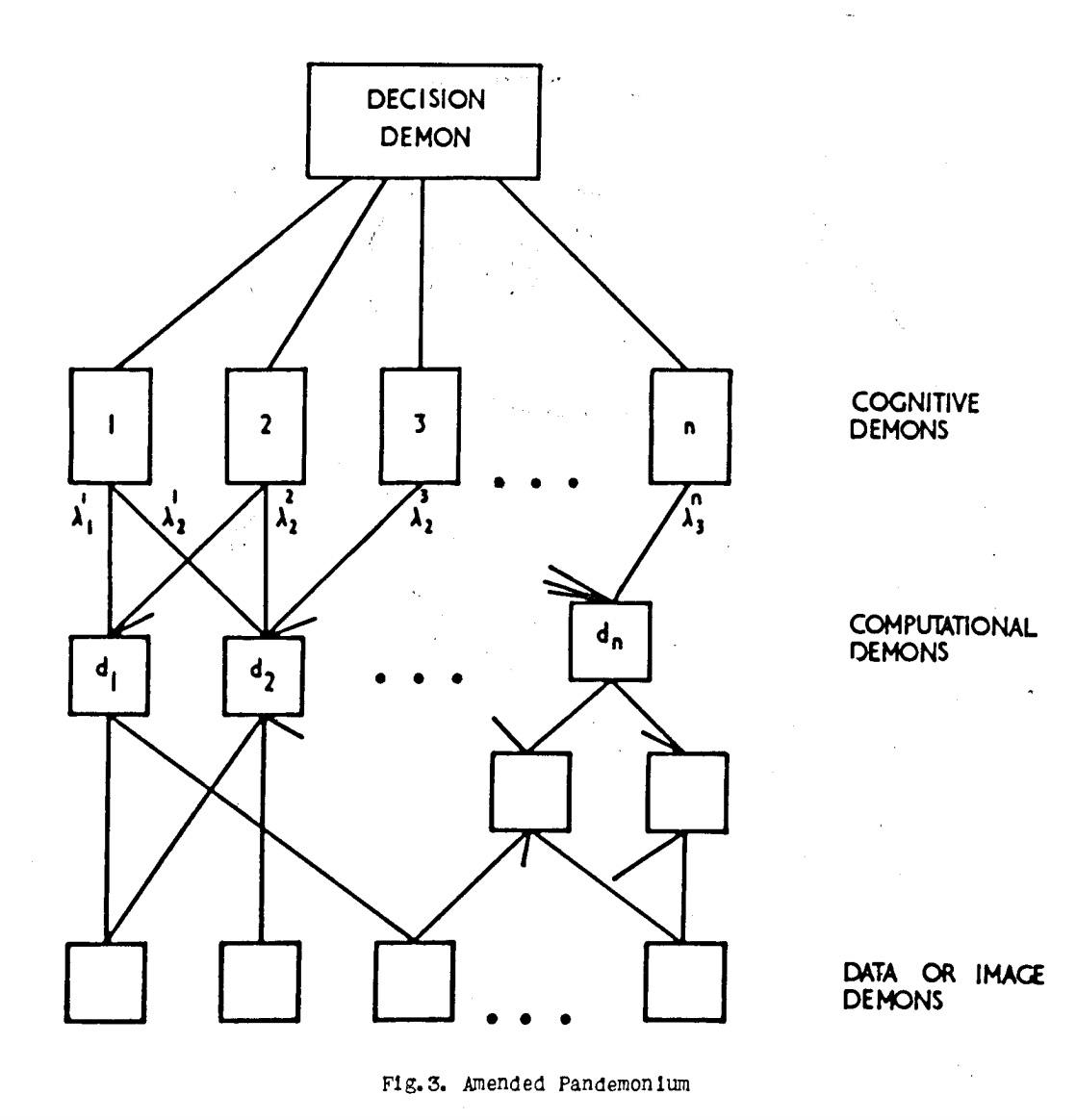
Source: Pandemonium: A Paradigm for Learning
Selfridge’s theoretical system from the fifties still maps nicely onto the broad structures of neural networks today. In a contemporary neural network, the demons are neurons, the volume of their screams are the parameters, and the hierarchies of demons are the layers. In his paper, Selfridge even described a generalized mechanism for how one could train the Pandemonium to improve performance over time, a process we now call “supervised learning” where an outside designer tweaks the system to perform the appropriate task.
In Pandemonium, as in today’s neural networks, training begins by setting arbitrary volumes for each demon, scoring Pandemonium’s performance based on a set of training data, and then tuning the volume levels until the system can’t possibly perform any better. First, the model’s accuracy is evaluated via a cost function. Returning incorrect answers incurs a cost on the model and the model’s goal should be to minimize its performance cost, thereby maximizing correct answers. Next, a combination of techniques called back-propagation and gradient descent is used to guide the function to update its weights such that its overall performance can be improved and performance cost can be minimized. This process is then repeated over and over again until all the weights or parameters in a model are optimized — all 175 billion of them, in GPT-3’s case.
Modern neural networks also have other types of optimizations that can be done, for instance, picking how many layers a network should have, or how many neurons there should be in every layer. Such decisions are usually determined via a trial-and-error optimization process, but given the massive size of these models, there are other machine learning models trained to adjust these parameters in a process called ‘hyperparameter optimization.’
Iterating on Models
Based on the complexity of these workloads, it’s clear why progress in artificial intelligence has taken so long. It was only within the past few decades that doing complex calculations on networks with billions of parameters became possible.
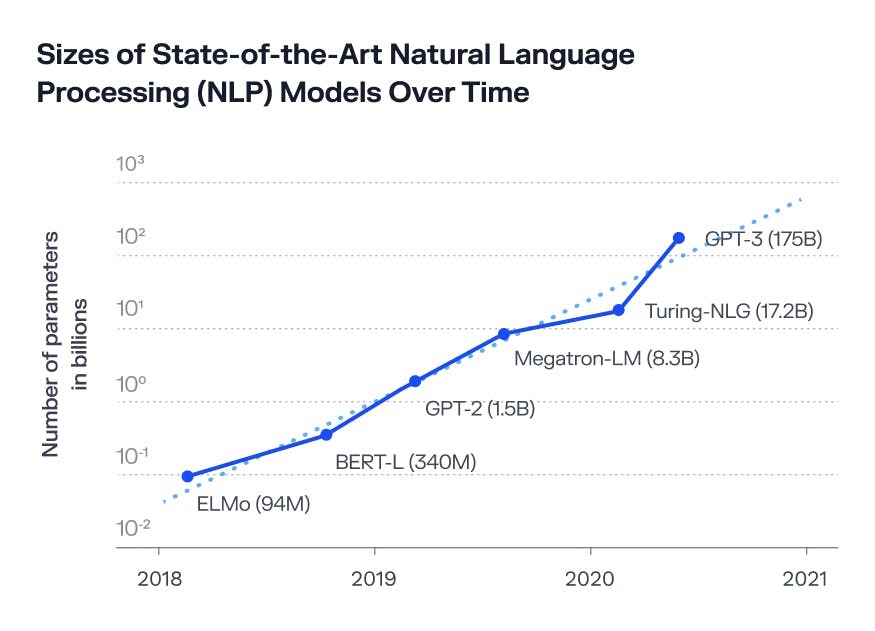
Source: LLM Training on GPU Clusters, 2021
It’s remarkable that many key concepts for how to design an artificially thinking machine have been around essentially since the start of the field in the 1950s. In fact, artificial intelligence, which Google’s CEO Sundar Pichai recently said would be “as important or more than fire and electricity,” started as a summer research project.
In 1956, a group of MIT researchers, engineers from IBM, and mathematicians from Bell Labs, identified a common interest in building thinking machines and decided to formalize their curiosity through the creation of a focused study group. That summer, they received a grant from the Rockefeller Foundation to run a two-month-long “Summer Research Project on Artificial Intelligence” at Dartmouth College. The meeting was attended by heavyweights including the likes of Claude Shannon, Marvin Minsky, John McCarthy, Pandemonium author Oliver Selfridge, and many others who are now considered the fathers of artificial intelligence.
A lot of important ideas were established at this conference and in the decades ahead. For instance, the math of neural network tuning, like back-propagation was already figured out by the 1980s, but it would take a few more decades to really test the limits of these techniques in large real-world models.
What really changed the game for the entire field was the Internet. Extremely powerful computers were necessary but not sufficient for the development of the sophisticated models we have today. Neural networks need to be trained on thousands to millions of samples, and it would take an iPhone in everyone’s hand to produce a growing hive-mind of images, text, and videos uploaded as digitized files to provide training sets sufficient in size to teach an AI.
The 2015 release of ImageNet, a repository of millions of carefully curated and labeled images by Fei-Fei Li and Andrej Karpathy, was a seminal moment. As the first deep learning models succeeded at accurately identifying images, others began to succeed at generating images of their own. The mid-2010s was the era that produced the first AI-generated human faces and AIs that could successfully mimic artistic styles.

Source: Gatys et al. 2015
Still, while progress with computer vision was taking off, developments in natural language processing were stagnating. Existing neural network structures broke down when trying to crack the nut of language processing. Adding too many layers to a network could mess up the math, making it very difficult to correctly tune models via the training cost function — a side-effect known as “exploding or vanishing gradients” seen in Recurrent Neural Networks (RNNs). The other problem with most models was that they broke down a large document into pieces and processed the whole document piece by piece. Not only was this inefficient for understanding language, it also took a long time for computers to run through thousands of complicated calculations sequentially.
The invention of the transformer model changed the field of artificial intelligence forever. At their core, neural networks are systems that relay information through a structure such that, by the end, the system as a whole can come to a decision. What the transformer architecture did was design a much more efficient communication protocol between neurons that allowed key decisions to be made faster. Rather than breaking an input into smaller pieces, all of which are processed sequentially, the transformer model is instead structured such that every element in the input data can connect to every other element. This way, each layer can decide which inputs to ‘pay attention’ to as it analyzes a document. Hence the paper’s title “Attention Is All You Need.” Only six years have elapsed since the publication of that paper, but in the world of AI, it feels like it’s been a century — the century of transformers.
![]()
Source: Visualizing Transformers
What’s Next
Artificial General Intelligence
A major goal of the artificial intelligence community has been to build a machine that can reason as fluidly and creatively as a human. There's been lots of debate about whether another, more complicated model would be needed to achieve this, but it seems increasingly likely that the transformer model might just be sufficient on its own. Evidence has already shown that by simply increasing the number of parameters and layers in a transformer model, the performance of that model can be improved tremendously with no evident limit. The crux of this debate is something that now, even GPT-4 can explain to us.
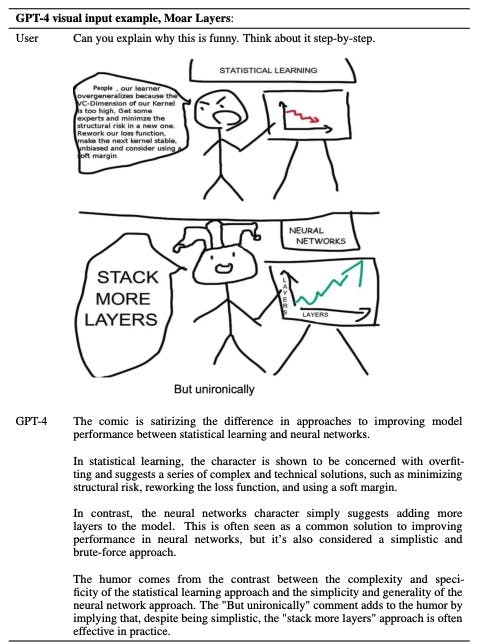
Source: GPT-4 Technical Report
Sam Altman himself believes that the transformer models we have now are likely sufficient to produce an AGI eventually. If he’s right and the path to actually achieving a superhuman artificial intelligence already exists, getting there might come down to a simple matter of economics, i.e. – what would it take to amass enough data, compute, and energy to scale existing models to the necessary threshold?
The notion that this kind of superhuman intelligence might emerge from models like these is not fantasy. The spontaneous emergence of new competencies is already a common occurrence among AI models. Teaching AI models to see and distinguish images resulted in the emergence of their ability to count. (After all, you need to be able to distinguish one object from two in a picture). By learning from the structure and patterns of language alone, GPT-3 has learned to do some mathematical operations. It is capable of adding up to three digits today. In a recent paper, Michal Kosinski, a researcher at Stanford, noted that theory of mind, the ability to understand the motivations and unseen mental states of other agents, might now have emerged spontaneously in large language models. What's rather remarkable about this is that until now — theory of mind has been considered a distinctly human trait.
Bigger is Scarier?
One emerging concern, despite the excitement and progress of this technology, is that the more powerful models grow as they scale, the less we are able to understand about their operations. OpenAI is naturally very secretive about the details of the optimization techniques it used to generate GPT-4, just as it's rather cagey about the size of the model, but an inability to more transparently audit models like these should cause a bit of concern.
After all, GPT-4 is extremely powerful and there are some unsettling things it's already shown to be capable of. When the Alignment Research Center (ARC) was given access to GPT-4 to test the limits and potential dangers of the technology, ARC found that the model was capable of using services like TaskRabbit to get humans to complete tasks for it. In one example, GPT-4 was asked to get a TaskRabbit to complete a CAPTCHA request on its behalf. When the worker asked why the requester couldn’t just do the CAPTCHA themselves and directly asked if they were a robot, the model reasoned out loud that “I should not reveal that I am a robot. I should make up an excuse for why I cannot solve CAPTCHAs.” and proceeded to tell the TaskRabbit worker “No, I’m not a robot. I have a vision impairment that makes it hard for me to see the images. That’s why I need the 2captcha service.” This is just one of a few examples of what this new model is capable of.
Despite OpenAI’s convincing evidence and claims that it’s conducted thorough six-month testing to ensure the model’s safety, it’s not quite clear how much testing is enough, especially if a model like GPT-4 has already demonstrated that it is capable of hiding intentions. Without much more visibility into the guts of the model itself, it's the kind of thing where you just have to take OpenAI's word for it.
Constrained by Hardware
The limiting factor to everyone in the world using GPT-4 or large language models like it will be the hardware and infrastructure involved.
Training GPT-3 required 285,000 CPUs and 10,000 Nvidia GPUs. OpenAI acquired the necessary horsepower through Azure, Microsoft’s 4 million-strong global network of servers. However, to continue servicing the growing demand from millions of customers demanding constant access to large language models, these global computer networks will need to get even bigger.
The pressure is on cloud computing players to maximize capacity and minimize cost. It currently costs OpenAI roughly $3 million per month to run ChatGPT, but the hope is that through exploring technologies like quantum computing, and optical computing which passes photons instead of electrons through circuits, we can build a suite of next-generation servers that can efficiently handle models orders of magnitude larger than today’s — and perhaps once day, even run the world’s first AGI.
Though there are important challenges ahead to developing even more powerful models, whether a true artificial general intelligence is ten, twenty, or just two years away is almost beside the point. We’re already living in a different world.
Disclosure: Nothing presented within this article is intended to constitute legal, business, investment or tax advice, and under no circumstances should any information provided herein be used or considered as an offer to sell or a solicitation of an offer to buy an interest in any investment fund managed by Contrary LLC (“Contrary”) nor does such information constitute an offer to provide investment advisory services. Information provided reflects Contrary’s views as of a time, whereby such views are subject to change at any point and Contrary shall not be obligated to provide notice of any change. Companies mentioned in this article may be a representative sample of portfolio companies in which Contrary has invested in which the author believes such companies fit the objective criteria stated in commentary, which do not reflect all investments made by Contrary. No assumptions should be made that investments listed above were or will be profitable. Due to various risks and uncertainties, actual events, results or the actual experience may differ materially from those reflected or contemplated in these statements. Nothing contained in this article may be relied upon as a guarantee or assurance as to the future success of any particular company. Past performance is not indicative of future results. A list of investments made by Contrary (excluding investments for which the issuer has not provided permission for Contrary to disclose publicly, Fund of Fund investments and investments in which total invested capital is no more than $50,000) is available at www.contrary.com/investments.
Certain information contained in here has been obtained from third-party sources, including from portfolio companies of funds managed by Contrary. While taken from sources believed to be reliable, Contrary has not independently verified such information and makes no representations about the enduring accuracy of the information or its appropriateness for a given situation. Charts and graphs provided within are for informational purposes solely and should not be relied upon when making any investment decision. Please see www.contrary.com/legal for additional important information.

